发布日期:2025-01-04 17:24 点击次数:147

剪辑:Aeneas 好困伪娘 户外
【新智元导读】OpenAI o1和o3模子的机密,竟传出被中国参议者「破解」?今天,复旦等机构的这篇论文引起了AI社区的好坏反响,他们从强化学习的角度,分析了罢了o1的阶梯图,并转头了现存的「开源版o1」。
就在今天,国内的一篇论文,引得公共AI学者恐慌不已。
推上多位网友暗意,OpenAI o1和o3模子背后究竟是何旨趣——这一未解之谜,被中国参议者「发现」了!


注:作家是对怎么靠拢此类模子进行了表面分析,并未宣称已经「破解」了这个问题
实质上,在这篇长达51页的论文中,来自复旦大学等机构的参议东谈主员,从强化学习的角度分析了罢了o1的阶梯图。
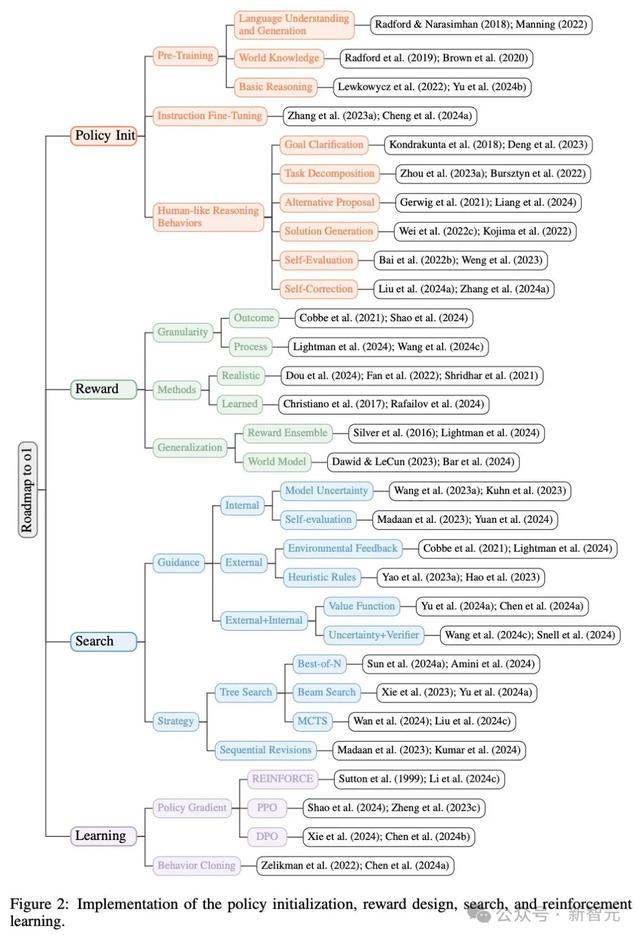
其中,有四个关键部分需要重心弯曲:策略运飘浮、奖励假想、搜索和学习。
此外,当作阶梯图的一部分,参议者还转头出了现存的「开源版o1」神志。

论文地址:https://arxiv.org/abs/2412.14135
探索OpenAI的「AGI之迷」
笼统来说,像o1这么的推理模子,不错被觉得是LLM和AlphaGo这类模子的相接。
最初,模子需要通过「互联网数据」进行检修,使它们简略交融文本,并达到一定的智能水平。
然后,再加入强化学习步履,让它们「系统地念念考」。
终末,在寻找谜底的过程中,模子会去「搜索」管制有筹备空间。这种步履既用于实质的「测试时」回报,也用于创新模子,即「学习」。
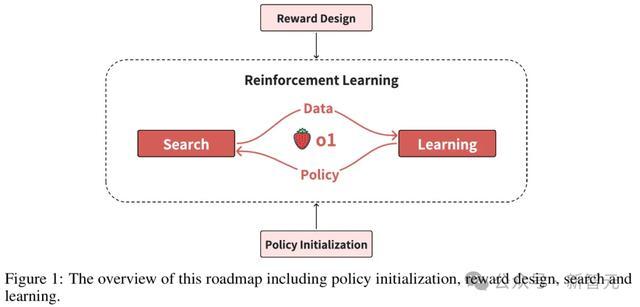
值得一提的是,斯坦福和谷歌在2022年的「STaR: Self-Taught Reasoner」论文中提议,不错哄骗LLM在回报问题之前生成的「推理过程」来微调改日的模子,从而提高它们回报此类问题的才略。
STaR让AI模子简略通过反复生成我方的检修数据,自我「招引」到更高的智能水平,表面上,这种步履不错让谈话模子特出东谈主类水平的智能。
因此,让模子「潜入分析管制有筹备空间」的这一理念,在检修阶段和测试阶段皆演出着关键变装。
在这项责任中,参议者主要从以下四个层面对o1的罢了进行了分析:策略运飘浮、奖励假想、搜索、学习。
策略运飘浮
策略运飘浮使模子简略发展出「类东谈主推理步履」,从而具备高效探索复杂问题解空间的才略。
海量文本数据预检修
指示微调
问题分析、任务判辨和自我纠正等学习才略
奖励假想
奖励假想则通过奖励塑造或建模提供密集有用的信号,带领模子的学习和搜索过程。
放浪奖励(基于最终放浪)
过程奖励(基于中间智商)
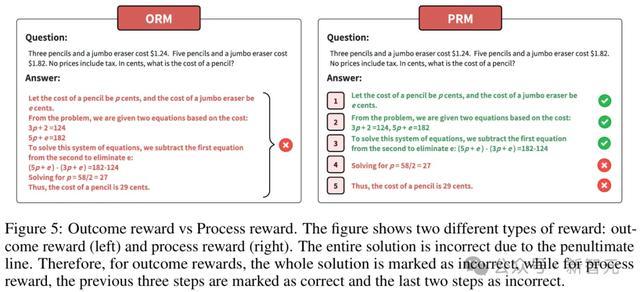
放浪奖励(左)和过程奖励(右)
搜索
搜索在检修和测试中皆起着至关进犯的作用,即通过更多计较资源不错生成更优质的管制有筹备。
MCTS等树搜索步履探索多种管制有筹备
聚会纠正迭代创新谜底
相接两种步履可能是最好选拔
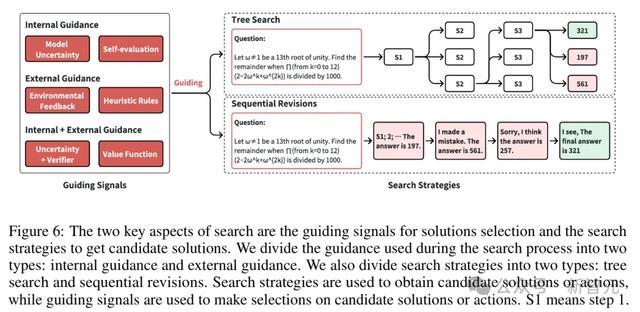
搜索过程中使用的带领类型:里面带领、外部带领,以及两者的相接
学习
从东谈主工众人数据中学习需要娴雅的数据标注。比较之下,强化学习通过与环境的交互进行学习,幸免了欣喜的数据标注资本,并有可能罢了特出东谈主类的推崇。
策略梯度步履,如PPO和DPO
从高质料搜索管制有筹备克隆步履
迭代搜索和学习周期
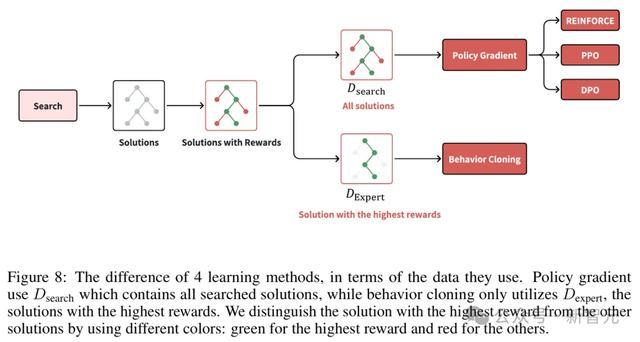
综上,正如参议者们在2023年11月所猜想的,LLM下一个冲破,很可能即是与谷歌Deepmind的Alpha系列(如AlphaGo)的某种相接。
对此,有网友暗意,这项参议的真谛真谛毫不单是是发表了一篇论文,它还为大广泛模子翻开了大门,让其他东谈主不错使用RL来罢了疏通的观念,提供不同类型的推理反馈,同期还开垦了AI不错使用的脚本和食谱。
「开源版o1」
参议者转头谈,尽管o1尚未发布时间通告,但学术界已经提供了多个o1的开源罢了。
此外,工业界也有一些雷同o1的模子,举例 k0-math、skywork-o1、Deepseek-R1、QwQ和InternThinker。
g1:这项参议可能是最早尝试从头罢了o1的神志。
Thinking Claude:与g1雷同,但它通过更复杂和细粒度的操作来辅导LLM。
Open-o1:神志提议了一个SFT数据集,其中每个反映皆包含CoT。参议者推测,这些数据可能来自东谈主类众人或一个强劲的LLM。
o1 Journey:通过两篇时间通告中进行了详备态状。第一部分通过束搜索生成的树数据进行遍历,特定节点由GPT-4优化后用于SFT,这一策略不错被态状为众人迭代。第二部分则尝试对o1-mini进行蒸馏,并通过prompt来复原荫藏的CoT过程。
Open-Reasoner:框架雷同于AlphaGo,通过强化学习提高模子性能。
慢念念考与LLM:参议相同分为两篇时间通告。第一部分与Open-Reasoner雷同,相接了强化学习和测试时的搜索。第二部分从QwQ和Deepseek-R1中蒸馏,并尝试了两种强化学习步履。
Marco-o1:神志将Open-o1的数据与模子本人通过MCTS算法生成的数据相接,用于SFT检修。
o1-coder:神志尝试在代码生成领域从头罢了o1。
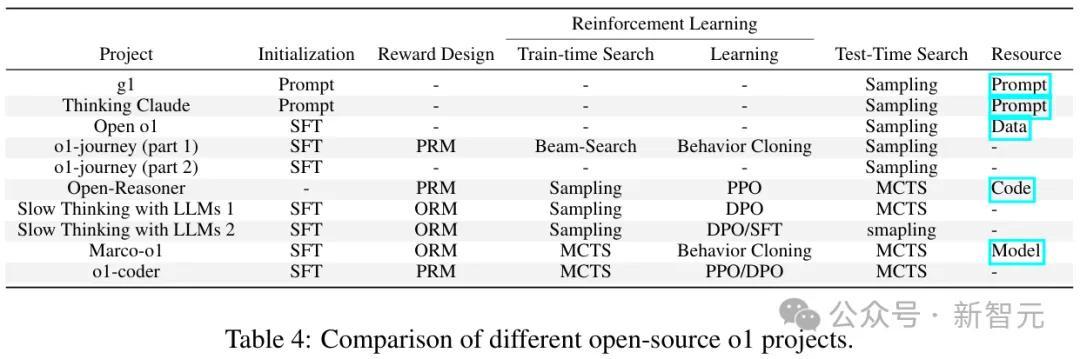
不同开源o1神志在策略运飘浮、奖励假想、搜索和学习领域的步履对比
策略运飘浮
在强化学习中,策略界说了智能体怎么凭证环境气象选拔行为。
其中,LLM的动作粒度分为三种级别:管制有筹备级别、智商级别和Token级别。
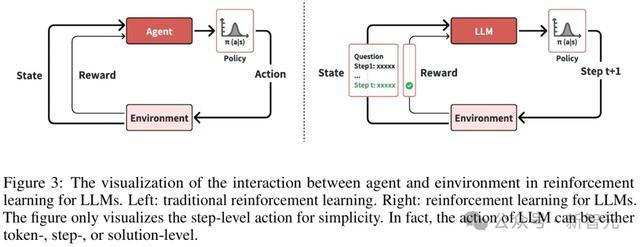
智能体与环境在LLM强化学习中的交互过程
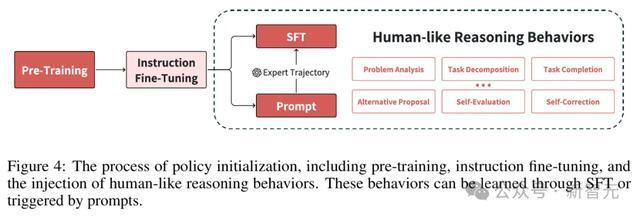
对于LLM的运飘浮过程,主要包括两个阶段:预检修和指示微调。
在预检修阶段,模子通过大边界麇集语料库的自监督学习,发展出基本的谈话交融才略,并谨守计较资源与性能之间的既定幂律端正。
在指示微调阶段,则是将LLM爽气单的下一个Token瞻望,蜕变为生成与东谈主类需求一致的反映。
对于像o1这么的模子,融入类东谈主推理步履对于更复杂的管制有筹备空间探索至关进犯。
预检修
预检修通过大边界文本语料库的宣战,为LLM成就基本的谈话交融和推理才略。
对于雷同o1的模子,这些中枢才略是后续学习和搜索中发展高等步履的基础。
谈话交融与生成:谈话交融是分线索发展的——句法形状较早显现,而逻辑一致性和抽象推理则在检修的后期阶段缓缓变成。因此除了模子边界外,检修时长和数据构成也至关进犯。
宇宙常识获取与存储:常识存储具有高效的压缩和泛化特质,而抽象观念比较事实性常识需要更泛泛的检修。
基础推理才略:预检修通过各种化的推理形状发展了基础推理才略,后者以爽气单推断到复杂推理的线索结构缓缓显现。
指示微调
指示微调通过在多领域的指示-反映付上进行有益检修,将预检修谈话模子蜕变为面向任务的智能体。
这一过程将模子的步履从单纯的下一个Token瞻望,蜕变为具有明确主义的步履。
恶果主要取决于两个关键身分:指示数据集的各种性和指示-反映付的质料。
类东谈主推理步履
尽管经过指示微调的模子展现了通用任务才略和用户意图交融才略,但像o1这么的模子,需要更复杂的类东谈主推理才略来充分阐明自后劲。
如表1所示,参议者对o1的步履形状进行了分析,识别出六种类东谈主推理步履。

问题分析:问题分析是一个关键的运飘浮过程,模子在管制问题前会先从头表述并分析问题。
任务判辨:在面对复杂问题时,东谈主类时常会将其判辨为多少可管制的子任务。
任务完成:之后,模子通过基于明确问题和判辨子任务的缓缓推理,生成管制有筹备。
替代有筹备:迎濒临推理阻遏或念念路中断时,生成各种化替代管制有筹备的才略尤为进犯。如表1所示,o1在密码破解中展现了这一才略,简略系统性地提议多个选项。
自我评估:任务完成后,自我评估当作关键的考证机制,用于证据所提管制有筹备的正确性。
自我纠正:当推理过程中出现可控诞妄时,模子会继承自我纠正步履来管制这些问题。在o1的演示中,当遭受诸如「No」或「Wait」之类的信号时,会触发纠正过程。
对于o1策略运飘浮的推测
策略运飘浮在开垦雷同o1的模子中起到了关键作用,因为它成就了影响后续学习和搜索过程的基础才略。
策略运飘浮阶段包括三个中枢构成部分:预检修、指示微调以及类东谈主推理步履的开垦。
尽管这些推理步履在指示微调后的LLM中已隐性存在,但其有用部署需要通过监督微调或用心假想的辅导词来激活。
长文本生成才略:在推理过程中,LLM需要讲究的长文本高下文建模才略。
合理塑造类东谈主推理步履:模子还需要发展以逻辑连贯边幅,有序安排类东谈主推理步履的才略。
自我反念念:自我评估、自我纠正和替代有筹备提议等步履,可视为模子自我反念念才略的推崇。
奖励假想
在强化学习中,智能体从环境中禁受奖励反馈信号,并通过创新策略来最大化其永久奖励。
奖励函数时常暗意为r(st, at),暗意智能体在时分步t的气象st下实践动作at所赢得的奖励。
奖励反馈信号在检修和推理过程中至关进犯,因为它通过数值评分明确了智能体的期许步履。
放浪奖励与过程奖励
放浪奖励是基于LLM输出是否相宜预界说期许来分派分数的。但由于贫寒对中间智商的监督,因此可能会导致LLM生成诞妄的解题智商。
与放浪奖励比较,过程奖励不仅为最终智商提供奖励信号,还为中间智商提供奖励。尽管展现了迢遥的后劲,但其学习过程比放浪奖励更具挑战性。
奖励假想步履
由于放浪奖励不错被视为过程奖励的一种非常情况,好多奖励假想步履不错同期应用于放浪奖励和过程奖励的建模。
这些模子常被称为放浪奖励模子(Outcome Reward Model,ORM)和过程奖励模子(Process Reward Model,PRM)。
来自环境的奖励:最平直的奖励假想步履是平直哄骗环境提供的奖励信号,或者学习一个模子来模拟环境中的奖励信号。
从数据中建模奖励:对于某些环境,环境中的奖励信号无法获取,也无法进行模拟。比较平直提供奖励,汇集众人数据或偏好数据更为容易。通过这些数据,不错学习一个模子,从而提供有用的奖励。
奖励塑造
在某些环境中,奖励信号可能无法有用传达学习主义。
在这种情况下,不错通过奖励塑造(reward shaping)对奖励进行从头假想,使其更丰富且更具信息量。
然而,由于价值函数依赖于策略π,从一种策略忖度的价值函数可能并不适和洽为另一种策略的奖励函数。
对于o1奖励假想的推测
鉴于o1简略处理多任务推理,其奖励模子可能相接了多种奖励假想步履。
对于诸如数学和代码等复杂的推理任务,由于这些任务的回报时常波及较长的推理链条,更可能继承过程奖励模子(PRM)来监督中间过程,而非放浪奖励模子(ORM)。
当环境中无法提供奖励信号时,参议者推测,o1可能依赖于从偏好数据或众人数据中学习。
凭证OpenAI的AGI五阶段运筹帷幄,o1已经是一个强劲的推理模子,下一阶段是检修一个简略与宇宙交互并管制实际问题的智能体。
为了罢了这一主义,需要一个奖励模子,为智能体在信得过环境中的步履提供奖励信号。
奖励集成:为通用任务构建奖励信号的一种直不雅边幅是通过特定领域的奖励集成。
宇宙模子:宇宙模子不仅简略提供奖励信号,还不错瞻望下一气象。有参议觉得,视频生成器不错当作一种宇宙模子,因为它简略瞻望改日时分步的图像。
搜索
对于像o1这么旨在管制复杂推理任务的模子,搜索可能在检修和推理过程中皆阐明进犯作用。
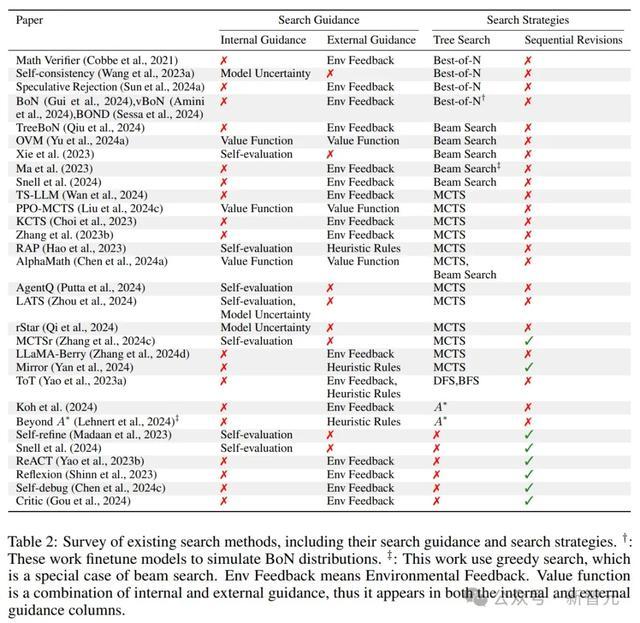
搜索带领
基于里面带领的搜索不依赖于来自外部环境或代理模子的信得过反馈,而是通过模子本人的气象或评估才略来招引搜索过程。
外部带领时常不依赖于特定策略,仅依赖于与环境或任务联系的信号来招引搜索过程。
同期,里面带领和外部带领不错相接起来招引搜索过程,常见的步履是相接模子本人的不笃定性与来自奖励模子的代理反馈。
搜索策略
参议者将搜索策略分为两种类型:树搜索和序列修正。
树搜索是一种全局搜索步履,同期生成多个谜底,用于探索更泛泛的管制有筹备范围。
比较之下,序列修恰是一种局部搜索步履,基于先前放浪缓缓优化每次尝试,可能具有更高的服从。
树搜索时常适用于复杂问题的求解,而序列修正更稳当快速迭代优化。
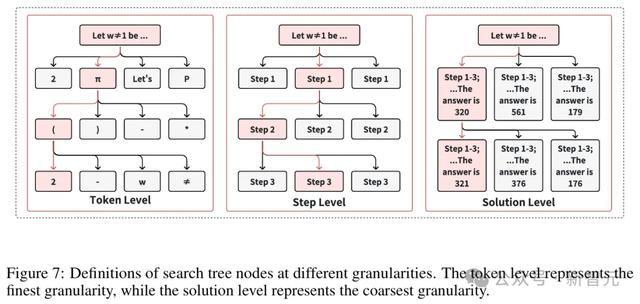
搜索在o1中的变装
参议者觉得,搜索在o1的检修和推理过程中,皆起着至关进犯的作用。
他们将这两个阶段中的搜索,分又名为检修时搜索(training-time search)和推理时搜索(test-time search)。
在检修阶段,在线强化学习中的试错过程也不错被视为一种搜索过程。
在推理阶段,o1标明,通过加多推理计较量和延伸念念考时分不错抓续提高模子性能。
参议者觉得,o1的「多念念考」边幅不错被视为一种搜索,哄骗更多的推理计较时分来找到更优的谜底。
对于o1搜索的推测
检修阶段搜索:在检修过程中,o1更可能继承树搜索时间,举例BoN或树搜索算法,并主要依赖外部带领。
推理阶段搜索:在推理过程中,o1更可能使用序列修正,相接里面带领,通过反念念不休优化和修正其搜索过程。
从o1博客中的示例不错看出,o1的推理作风更接近于序列修正。各种迹象标明,o1在推理阶段主要依赖里面带领。
学习
强化学习时常使用策略对轨迹进行采样,并基于赢得的奖励来创新策略。
在o1的配景下,参议者假定强化学习过程通过搜索算法生成轨迹,而不单是依赖于采样。
基于这一假定,o1的强化学习可能波及一个搜索与学习的迭代过程。
在每次迭代中,学习阶段哄骗搜索生成的输出当作检修数据来增强策略,而创新后的策略随后被应用于下一次迭代的搜索过程中。
检修阶段的搜索与测试阶段的搜索有所不同。
参议者将搜索输出的气象-动作对麇集记为D_search,将搜索中最优管制有筹备的气象-动作对麇集记为D_expert。因此,D_expert是D_search 的一个子集。
学习步履
给定D_search,可通过策略梯度步履或步履克隆来创新策略。
近端策略优化(PPO)和平直策略优化 DPO)是LLM中最常用的强化学习时间。此外,在搜索数据上实践步履克隆或监督学习亦然常见作念法。
参议者觉得,o1的学习可能是多种学习步履相接的放浪。
在这一框架中,他们假定o1的学习过程从使用步履克隆的预热阶段脱手,当步履克隆的创新恶果趋于认知后,转向使用PPO或DPO。
这照旧由与LLama2和LLama3中继承的后检修策略一致。

强化学习的Scaling Law
在预检修阶段,亏欠、计较资本、模子参数和数据边界之间的关系,是谨守幂律Scaling Law的。那么,对于强化学习,是否也会推崇出来呢?
凭证OpenAI的博客,推感性能与检修时分计较量,确乎呈对数线性关系。然而,除了这极少以外,联系参议并未几。
为了罢了像o1这么的大边界强化学习伪娘 户外,参议LLM强化学习的Scaling Law至关进犯。
